写真や動画、ソースコード、生成AIの成果物など、私たちが日々生み出すデータは年々膨張し続けています。便利さの裏側で、「消えたら終わり」という不安を抱えたまま、場当たり的なバックアップに頼っていないでしょうか。
実際、ランサムウェアや不正アクセスは企業だけでなく、個人やSOHO環境にも確実に広がっています。注意して使う、こまめに保存する、といった人間の努力だけでは防げない時代に入りました。
そこで本記事では、2026年時点で現実的かつ最強といえるバックアップの考え方を整理します。キーワードは「自動化」と「イミュータビリティ」です。人が忘れても、攻撃されても、データだけは残る仕組みをどう作るのか。
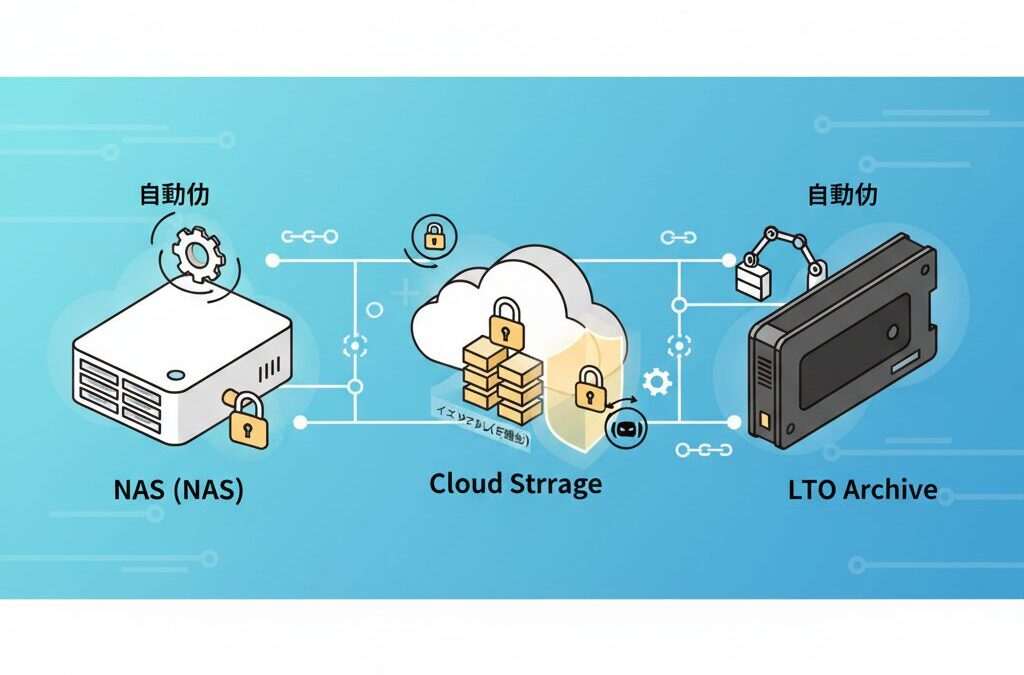
NASや最新HDD、クラウドストレージ、さらにはLTOテープまで含め、ガジェット好きの視点で分かりやすく解説します。読み終えたとき、あなたのバックアップは“作業”から“設計”へと変わっているはずです。
データが消える本当の理由とバックアップ設計の限界
データが消える理由は、単純な「保存し忘れ」ではありません。2026年現在、最大の要因はデジタル・エントロピーの増大と人間の介在にあります。スマートフォンの8K動画、生成AIのログ、仮想マシンのイメージなど、個人が扱うデータ量はTB級が当たり前になりました。情報理論で知られるエントロピーの法則が示す通り、秩序あるデータは放置すれば破損や消失へと向かいます。
そこに追い打ちをかけるのが外的脅威です。独立行政法人情報処理推進機構によれば、ランサムウェアは長年にわたり最重要脅威であり続けています。特に近年はRaaSの普及により、個人やSOHOのNASも無差別に狙われています。攻撃者は金銭的価値ではなく、思い出や業務継続への心理的ダメージを人質にします。
さらに見落とされがちなのが物理的限界です。HDDにはビット腐敗、SSDには通電しない状態でのデータ保持期限があります。東京商工リサーチの調査では、情報漏えい・紛失事故の原因の6割以上が不正アクセスやマルウェアでしたが、これは「注意深く使う」だけでは防げない現実を示しています。
| 消失要因 | 具体例 | 従来バックアップの弱点 |
|---|---|---|
| ヒューマンエラー | 上書き保存、誤削除 | 手動運用では再発防止が困難 |
| 外的攻撃 | ランサムウェア | 常時接続バックアップも同時破壊 |
| 物理劣化 | ビット腐敗、電荷抜け | 定期検証をしないと気付けない |
ここで重要なのが、バックアップ設計そのものにも限界があるという視点です。古典的な3-2-1ルールは確率論的には有効ですが、論理破壊には弱い構造です。バックアップ先がネットワークに接続され、書き込み可能である限り、攻撃者や誤操作の影響範囲から逃れられません。
多くのデータ消失事例を分析すると、失敗の本質は「人が運用する前提」にあります。「後でやる」「重要なものだけ残す」といった判断が介在した瞬間、システムは不完全になります。セキュリティ研究者の間では、バックアップ作業に人間を関与させること自体がリスクだという認識が一般化しています。
つまり、データが消える本当の理由は技術不足ではなく設計思想にあります。自動化されず、不変性もなく、検証されないバックアップは、存在していても守りになりません。この限界を直視することが、次の一手を考える出発点になります。
3-2-1ルールから3-2-1-1-0へ進化した最新バックアップ哲学
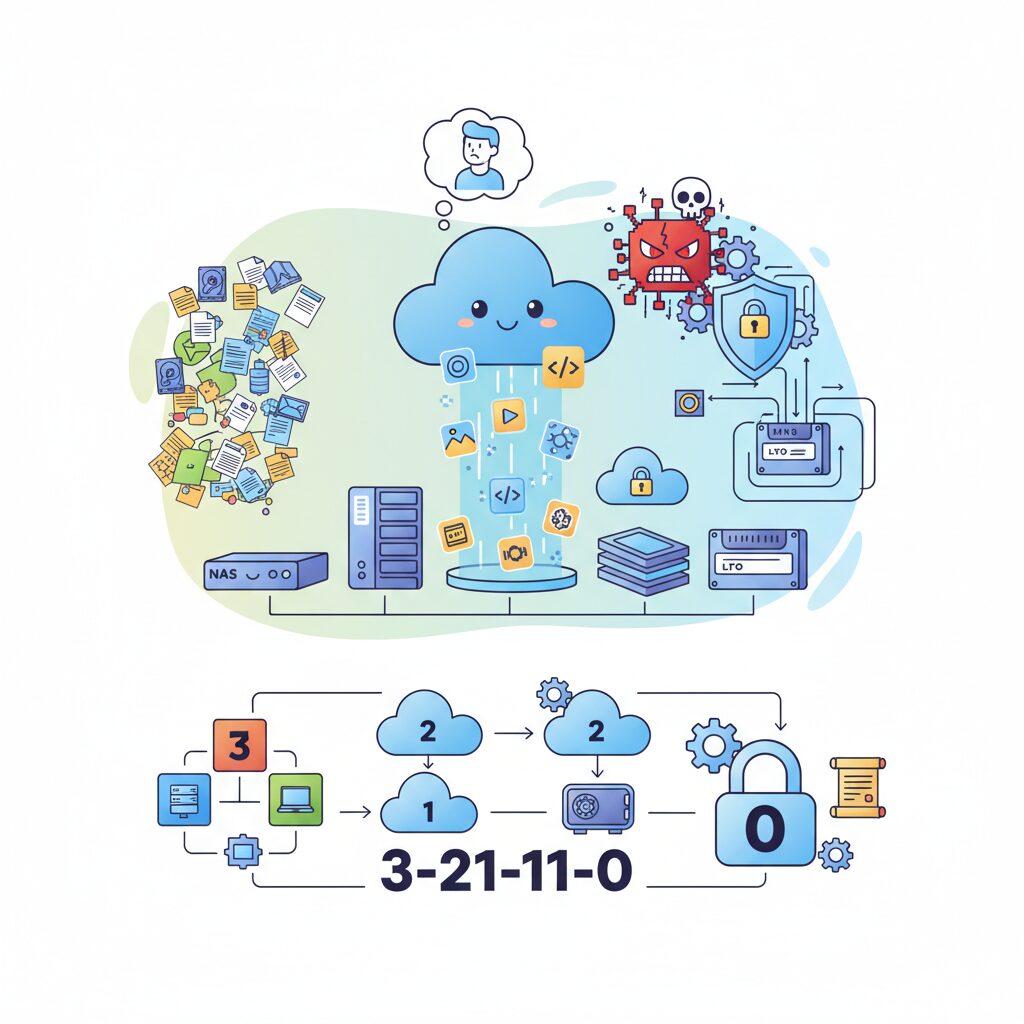
従来の3-2-1ルールは、長年にわたりバックアップの黄金律として機能してきましたが、2026年の脅威環境ではそれだけでは不十分ですます。最大の変化は、物理的故障ではなく論理的破壊、つまりランサムウェアを前提に設計する必要が出てきた点です。複数コピーや異なるメディアを用意していても、それらが常時ネットワークに接続されていれば、同時に暗号化されるリスクを避けられません。
この課題に対する回答が、3-2-1-1-0という進化形のバックアップ哲学ですます。米国のCISAなどの公的機関も推奨しており、世界的に「新しい常識」として定着しつつあります。ポイントは、従来ルールに二つの概念を追加したことにあります。
| 要素 | 追加・拡張の意味 | 防げるリスク |
|---|---|---|
| +1(オフライン/不変) | ネットワークから隔離、またはWORM化 | ランサムウェア、内部不正 |
| 0(エラー) | 復元テストを前提に品質を担保 | 壊れたバックアップ |
特に重要なのが「1つのオフライン、またはイミュータブルなコピー」ですます。これはエアギャップされたHDDやテープのような物理的隔離だけでなく、クラウドやNASにおける論理的な書き換え不能状態も含みます。一度保存したデータが、管理者権限を持ってしても削除・改変できない仕組みは、攻撃者にとって最後まで突破できない壁になります。
実際、Amazon S3のObject LockやSynologyのImmutable Snapshotのような機能は、WORM特性をストレージレベルで強制します。ストレージ研究者の間でも、不変性は「バックアップの最終防衛線」と位置付けられており、NISTのガイドラインでもランサムウェア対策として言及されています。
もう一つの進化が「0エラー」という考え方ですます。これは理想論ではなく、復元テストを自動化することで実現可能な現実的目標です。バックアップ業界では「復元できないバックアップは存在しないのと同じ」と言われており、定期的な検証なしでは安全性を担保できません。
3-2-1-1-0は、バックアップを単なる保険から、攻撃を受けることを前提としたレジリエントなシステム設計へと昇華させる哲学ですます。人の注意力や善意に依存せず、仕組みそのものがデータを守る。この発想の転換こそが、現代のガジェット環境において最も価値のあるアップデートと言えます。
イミュータビリティとは何か──ランサムウェア時代の最後の砦
イミュータビリティとは、一度保存されたデータが、定められた期間中は誰にも、いかなる権限でも書き換えや削除ができない状態を指します。これは単なるアクセス制御や読み取り専用設定とは本質的に異なります。管理者権限を奪取したランサムウェアであっても、ストレージ自体が拒否するため、論理的破壊が成立しません。
この概念が注目される背景には、攻撃手法の変化があります。近年のランサムウェアは、まずバックアップを探し出し、削除や暗号化を行ってから本番データを人質に取ります。米国CISAが提唱する3-2-1-1-0戦略で「1つのイミュータブルコピー」が最重要視されるのは、この攻撃シナリオを前提にしているからです。
技術的には、WORM(Write Once Read Many)という仕組みで実現されます。ファイルシステムやオブジェクトストレージが保持期間を内部的に管理し、削除APIや上書き命令そのものを無効化します。Amazon S3のObject Lockや、SynologyのImmutable Snapshotは代表例で、いずれもストレージ層で不変性を強制します。
| 観点 | 通常のバックアップ | イミュータブルバックアップ |
|---|---|---|
| 削除権限 | 管理者なら可能 | 管理者でも不可 |
| ランサムウェア耐性 | 低い | 極めて高い |
| 内部不正対策 | 限定的 | 強力 |
重要なのは、イミュータビリティが「バックアップの成功率」を高めるのではなく、最後に必ず残るコピーを保証する思想だという点です。復元時点を過去に固定できるため、攻撃の侵入がいつ起きたのか不明なケースでも、安全な状態まで確実に時間を巻き戻せます。
実際、Synologyの公式ドキュメントでも、不変スナップショットは「管理者の誤操作やマルウェアからの最終防衛線」と位置付けられています。東京商工リサーチの調査で不正アクセスが情報漏えい原因の6割を超えた事実を踏まえると、人間の注意力に依存しない仕組みの価値は明らかです。
ランサムウェア時代において、侵入を完全に防ぐことは現実的ではありません。だからこそ、侵入後も破壊されないデータを残すという発想が必要です。イミュータビリティは派手な機能ではありませんが、静かに、確実に機能する最後の砦として、バックアップ戦略の中核を担っています。
日本で増える個人・SOHO被害と統計が示す現実
日本におけるサイバー被害は、もはや大企業や官公庁だけの問題ではありません。近年、被害の重心は明確に個人やSOHOへと移りつつあります。独立行政法人情報処理推進機構が公表した「情報セキュリティ10大脅威2025」では、組織向けだけでなく個人編においてもフィッシングや不正ログインが常態化した脅威として位置づけられています。特に注目すべき点は、攻撃手法の高度化ではなく、攻撃の敷居が極端に下がったことです。
Ransomware as a Serviceの普及により、専門知識の乏しい攻撃者でも既製のツールを使って無差別攻撃を仕掛けられる時代になりました。結果として、**常時接続された個人NASやSOHOのファイルサーバーが、費用対効果の高い標的として狙われています**。実際、IPAの個人向け解説資料でも、自宅ネットワーク機器の設定不備や更新遅延が被害拡大の要因として繰り返し指摘されています。
この傾向を裏付けるのが、東京商工リサーチによる統計です。同社が公表した2024年の調査では、上場企業およびその子会社における個人情報漏えい・紛失事故は189件と過去最多を記録しました。重要なのは件数そのものではなく、その原因構成の変化です。
| 主な原因 | 構成比 | 示唆されるリスク |
|---|---|---|
| ウイルス感染・不正アクセス | 60.3% | 外部攻撃による制御不能リスク |
| 誤操作・設定ミス | 約20% | 人為的対策の限界 |
| 紛失・盗難 | 約10% | 物理管理の甘さ |
このデータが示しているのは、「注意して使う」「気をつけて管理する」といった人的努力だけでは、もはや被害を防げないという現実です。ゼロデイ脆弱性やVPN機器の欠陥を突く攻撃は、利用者のリテラシーとは無関係に成立します。**人が正しく振る舞うことを前提にした防御モデルは、統計的に破綻しつつある**といえます。
個人やSOHOの場合、被害が表面化しにくい点も問題です。企業のように公表義務がないため、暗号化された写真や業務データを失っても、届出や統計に反映されないケースが大半です。IPAの関係者も、公開されている数字は氷山の一角にすぎないと指摘しています。実被害ベースでは、個人領域のデータ消失ははるかに多いと考えるのが自然です。
さらに厄介なのは、攻撃者が金銭的価値より心理的価値を狙っている点です。家族写真、制作途中の原稿、顧客データといった「代替不能なデータ」は、数万円から数十万円の身代金でも支払われやすいとされています。**被害者の感情そのものが、換金可能な資産として見なされている**のが現在の脅威環境です。
統計が示す現実は明確です。日本では今後も、個人とSOHOがサイバー被害の主戦場になります。この事実を直視したとき、データ保全はもはや趣味や保険ではなく、日常インフラの一部として再定義される段階に来ています。
30TB時代のHDDと磁気テープLTOの正しい使い分け
30TB級HDDが現実的な価格で入手できるようになった2026年、バックアップ用途におけるHDDと磁気テープLTOの関係は「競合」ではなく役割分担として捉える必要があります。どちらも大容量ですが、設計思想と守備範囲は根本的に異なります。
まずHDDは、HAMR技術の実用化により30TB超という容量を単一ドライブで提供しつつ、ランダムアクセス性を維持しています。SeagateやWestern Digitalの公式ロードマップでも示されている通り、HDDは今後も「頻繁に読み書きされる大容量データ」の主役です。バックアップにおいては、NASに組み込まれたHDDが自動スナップショットや世代管理を担い、復元までの時間を最小化します。
一方でLTOは、LTOコンソーシアムが公開している仕様が示す通り、LTO-10でネイティブ40TBという圧倒的な容量密度を実現しています。ただし、アクセスはシーケンシャルが前提で、ドライブ自体も高価です。その代わり、物理的にネットワークから切り離せるエアギャップという、HDDには決して真似できない特性を持ちます。
| 観点 | 30TB級HDD | LTO磁気テープ |
|---|---|---|
| アクセス特性 | 高速ランダムアクセス | シーケンシャルのみ |
| 主用途 | 日常バックアップ・迅速な復元 | 長期アーカイブ・最終防衛線 |
| ランサムウェア耐性 | 論理対策が必須 | 物理的に極めて高い |
この違いを踏まえると、正解は明確です。HDDは「すぐ戻せる保険」、LTOは「滅多に使わないが絶対に失われない金庫」として使い分けます。例えば、8K動画や仮想マシンのイメージはHDDベースのNASで日次バックアップし、四半期ごとに確定版だけをLTOへ書き出します。
米国の大規模研究機関や放送局が今なおLTOを採用し続けている事実が示す通り、長期保存コストと信頼性のバランスではLTOは無敗です。30TB時代だからこそ、HDDの万能感に頼らず、媒体の物理特性を理解した使い分けがデータ保全の完成度を一段引き上げます。
NASを中核にした自動バックアップ環境の作り方
NASを中核にした自動バックアップ環境を構築する際の本質は、NASを単なる保存先ではなく「自律的に判断し動く司令塔」として設計する点にあります。人が操作する前提を排し、端末・サーバー・クラウドを束ねるハブとして振る舞わせることで、デジタル・エントロピーに対抗できます。
まず重要なのは、バックアップ対象をNAS側で一元管理する発想です。各PCやサーバーに個別のバックアップ設定を散在させると、設定漏れや停止に気づけません。SynologyのActive Backup for BusinessやQNAPのHBS 3のように、NASがエージェントを通じて端末を制御する方式であれば、**バックアップの成否をNAS一か所で可視化できます**。
| 要素 | 役割 | 自動化のポイント |
|---|---|---|
| NAS本体 | バックアップ司令塔 | 24時間稼働と通知設定 |
| クライアント端末 | データ生成源 | エージェント常駐で操作不要 |
| スナップショット | 即時復旧ポイント | 時間単位で自動取得 |
次に設計すべきは、NAS内部で完結する一次防御です。BtrfsやZFSのスナップショット機能を活用すれば、数TB規模でも数秒で復元ポイントを生成できます。SynologyのImmutable Snapshotのように不変性を付与すると、管理者権限を奪われても削除できません。これは米国CISAが提唱する3-2-1-1-0戦略とも整合します。
さらに実践的なのが、NASを起点とした多段バックアップです。NASが受け取ったデータを、夜間に自動で別ボリュームや外部NASへ複製し、同時にクラウドへ転送します。QNAP HBS 3のQuDedupやSynology Hyper Backupの重複排除を使えば、転送量を50〜70%削減できるとされています。
重要なのはスケジュール設計です。業務時間中はクライアントからNASへの高速バックアップ、深夜帯はNASからオフサイトへの転送と役割を分けます。これによりネットワーク負荷を抑えつつ、**人が介在しない完全自動フロー**が成立します。
最後に欠かせないのが監視です。バックアップが「成功した通知」だけでは不十分で、「実行されなかった沈黙」を検知する必要があります。NASから定期的に外部監視サービスへシグナルを送る仕組みを組み込むことで、停止や障害を即座に把握できます。バックアップ専門家の間で語られる「復元できて初めてバックアップ」という原則は、NAS中心設計によって初めて現実的になります。
Docker・仮想環境を安全に守るバックアップ手法
Dockerや仮想マシンは、環境を素早く再現できる反面、バックアップ設計を誤ると一瞬で全サービスを失う危険性があります。特に注意すべきなのは、コンテナそのものではなく、永続化されたデータと構成情報です。**安全なバックアップとは「再起動できる」ではなく「同じ状態に戻せる」こと**を意味します。
Docker環境では、イメージは再取得できますが、データベースや設定ファイルが保存されるボリュームは唯一無二です。The Polyglot Developerによれば、稼働中のデータベースボリュームを単純コピーすると、WALやトランザクション不整合により復元不能になる事例が多発しています。そのため、アプリケーションを認識したバックアップが必須です。
具体的には、mysqldumpやpg_dumpで一貫性のあるダンプを取得し、それをResticやBorgBackupでスナップショット化します。Resticは暗号化がデフォルトで強制され、S3互換ストレージに直接保存できるため、BackblazeやWasabiと組み合わせたオフサイト運用に適しています。BorgBackupはローカルやSSH越しで高い重複排除率を誇り、家庭内NASとの相性が良好です。
| 対象 | 推奨手法 | 理由 |
|---|---|---|
| Dockerボリューム | ダンプ+重複排除バックアップ | DB整合性と容量効率を両立 |
| docker-compose.yml | Git管理+定期バックアップ | 構成再現性を保証 |
| 仮想マシン | スナップショット+イメージ保存 | 障害時の即時復旧 |
仮想マシンの場合、スナップショット機能を過信しないことも重要です。VMwareやKVMのスナップショットは短期保護には有効ですが、長期間保持するとI/O性能低下や破損リスクが高まります。米国NISTのガイドラインでも、スナップショットはバックアップの代替ではないと明記されています。
最終的な防衛線となるのがイミュータブルバックアップです。NAS側で不変スナップショットを有効化し、さらにクラウド側でもObject Lockを設定することで、管理者権限を奪われても過去データは削除されません。**仮想環境は攻撃者にとって価値が高い標的だからこそ、二重三重の隔離が不可欠**です。
自動化されたバックアップと定期的な復元テストを組み合わせることで、Dockerや仮想環境は「壊れやすい実験場」から「信頼できる基盤」へと変わります。環境を作る自由と、失っても取り戻せる安心感。その両立こそが、現代の仮想化バックアップのゴールです。
クラウドストレージ選定とコスト最適化の考え方
クラウドストレージ選定で最初に意識すべきは、単純な容量単価ではなく、**「復元まで含めた総コスト」をどう抑えるか**という視点です。バックアップ用途では、平時はほとんどアクセスせず、有事には一気に大量のデータを取り出すという極端な使い方になります。この特性を理解せずに選ぶと、いざ復元する段階で想定外の請求に直面します。
特に重要なのが下り転送料金、いわゆるEgress Feeです。Amazon S3やAzure Blobなどのメジャーサービスは信頼性が高い一方、ダウンロード時に高額な料金が発生します。これはクラウド経済学の基本構造で、AWSの公式ドキュメントでも「データの取り出しが主な収益源」であることが示唆されています。バックアップの復元テストをためらわせる料金体系は、結果的にリスクを高めます。
| サービス | ストレージ単価目安 | 下り転送 | バックアップ適性 |
|---|---|---|---|
| Wasabi | 約7ドル/TB/月 | 無料 | 頻繁な復元テスト向き |
| Backblaze B2 | 約6ドル/TB/月 | 低額 | コスト重視で柔軟 |
| S3 Glacier Deep Archive | 約1ドル/TB/月 | 高額 | 長期保管専用 |
このように見ると、「安いから最適」とは一概に言えないことが分かります。例えばGlacier Deep Archiveはテープ並みの低価格ですが、復元に時間がかかり、即時性が求められる個人やSOHO用途では現実的ではありません。一方、WasabiやBackblaze B2は**復元を前提にした価格設計**で、バックアップ本来の目的に忠実です。
次に考えるべきがデータ量の増え方です。生成AIのログや動画素材のように、差分が多く実体は似ているデータでは、重複排除と圧縮がコスト最適化の鍵になります。ResticやQNAPのQuDedupは、米国のバックアップ研究コミュニティでも高い削減率が報告されており、50〜70%程度の容量削減は珍しくありません。転送量が減ることで、帯域と料金の双方を抑えられます。
さらに、イミュータブル設定の期間設計も重要です。ランサムウェア対策としてObject Lockを長期間設定すると安全性は高まりますが、古い世代のデータが削除できず、ストレージは雪だるま式に増えます。**7日から30日程度をクラウドで保持し、それ以前はローカルやオフライン媒体に逃がす**という二層構造が、コストと安全性のバランスが取れた現実解です。
クラウドストレージは「無限に見える箱」ですが、課金体系は極めて現実的です。復元頻度、データの性質、保持期間を冷静に分解し、自分の使い方に最も摩擦が少ないサービスを選ぶことが、結果として長く安定したバックアップ運用につながります。
失敗に気づくための監視と自動復元テスト
バックアップで最も危険なのは、失敗そのものではなく失敗に気づけないことです。自動化されたバックアップ環境では、処理が静かに止まり、そのまま数週間、数カ月放置されるケースが少なくありません。米国CISAやNISTのガイドラインでも、バックアップは取得よりも監視と検証が重要だと繰り返し指摘されています。
まず重視すべきは「沈黙」を検知する監視設計です。多くのツールは成功時のみ通知を送りますが、これは致命的な欠陥を抱えています。ジョブが実行されなかった場合、通知自体が発生しないからです。そこで有効なのが、いわゆるデッドマンズスイッチ型の監視です。これは一定時間ごとに外部監視サービスへ生存信号を送信し、信号が途絶えた場合に異常として通知する仕組みです。
この方式は個人環境でも導入しやすく、バックアップスクリプトの末尾にHTTPリクエストを1行追加するだけで実現できます。LinuxやNAS、Docker環境を問わず共通して使えるため、異なるバックアップ手法を混在させている環境ほど効果を発揮します。
| 監視対象 | 検知できる異常 | 実用上の価値 |
|---|---|---|
| 実行間隔 | ジョブ未実行、スケジューラ停止 | バックアップ自体の消失を防ぐ |
| 終了ステータス | 途中失敗、容量不足 | 不完全なバックアップを排除 |
| 最終成功時刻 | 長期間の放置状態 | 人的確認の頻度を下げる |
しかし監視だけでは不十分です。バックアップは復元できて初めて意味を持つからです。実際、バックアップデータ自体が破損していた、暗号鍵を失っていた、依存関係が欠落していたという理由で復元に失敗する事例は少なくありません。Google SREの公開資料でも、障害時に初めて復元テストを行う運用は高リスクだと明言されています。
そこで重要になるのが自動復元テストです。近年のバックアップソフトウェアやNASでは、取得したバックアップを隔離環境で自動的に起動・展開し、最低限の動作確認を行う仕組みが実装されています。OSが起動するか、ファイルシステムがマウントできるか、指定ファイルのチェックサムが一致するかといった検証を、夜間や週次で無人実行できます。
特に仮想マシンやPCイメージのバックアップでは、この仕組みが威力を発揮します。復元テスト用に一時的な仮想環境を立ち上げ、スクリーンキャプチャやログを自動保存することで、人間は結果レポートを見るだけで済みます。これにより「最後に復元テストをしたのはいつか分からない」という状態から脱却できます。
監視と自動復元テストを組み合わせることで、バックアップは単なる保険から、常に機能が保証されたインフラへと進化します。人間が定期的に確認しなくても、システム自身が異常を検知し、復元可能性を証明し続ける。この仕組みこそが、3-2-1-1-0戦略における最後の「0エラー」を現実のものにします。
人を信用しない仕組みがもたらすデータの平和
人を信用しない仕組みとは、誰かが正しく操作することや、善意を持ち続けることを前提にしない設計のことです。
一見すると冷たく聞こえますが、データ保全の世界ではこれが最も人に優しい思想になります。
判断、記憶、注意力といった人間の弱点を、最初からシステム側で無効化するからです。
IPAやCISAなどの公的機関が繰り返し指摘している通り、近年のデータ損失の主因は「不注意」よりも「想定外の侵害」です。
管理者自身が被害者になるケースも多く、善悪や熟練度はもはや関係ありません。
だからこそ信頼ではなく制約で守るという発想が重要になります。
その象徴がイミュータビリティです。
一度書き込んだデータを、管理者権限であっても消せない、改ざんできない状態を強制します。
Amazon S3のObject Lockや、Synology・QNAPの不変スナップショットは、内部不正やランサムウェアを「操作不能」に追い込みます。
| 観点 | 人を信用する設計 | 信用しない設計 |
|---|---|---|
| 削除操作 | 権限者なら可能 | 保持期間中は不可 |
| 攻撃耐性 | 判断ミスに依存 | システムが拒否 |
| 心理的負荷 | 常に注意が必要 | 意識しなくてよい |
ここに自動化が組み合わさることで、状況はさらに変わります。
バックアップが成功したか失敗したかを人が確認する必要はなくなります。
実行されなかった事実だけを検知する監視が、静かな異常を確実に可視化します。
研究者のブリュース・シュナイアー氏が指摘するように、優れたセキュリティとは「正しい行動を強制する仕組み」です。
人を訓練するのではなく、失敗できない構造を作る。
その結果として得られるのが、データに対する恒常的な安心感です。
人を信用しない仕組みは、疑心暗鬼を生みません。
むしろ誰もが失敗する前提を受け入れることで成立する平和をもたらします。
データが静かに守られているという確信は、ガジェットやシステムを楽しむ余裕そのものなのです。
参考文献
- IPA(情報処理推進機構):情報セキュリティ10大脅威 2025
- 東京商工リサーチ:2024年上場企業の個人情報漏えい・紛失事故調査
- Synology Inc.:How Btrfs protects your company’s data
- QNAP:How to Protect Data from Ransomware with S3 Object Lock in HBS 3
- LTO Consortium:Ultrium LTO Roadmap
- TechRadar:Seagate launches biggest hard drive ever — 30TB Exos Mozaic 3+